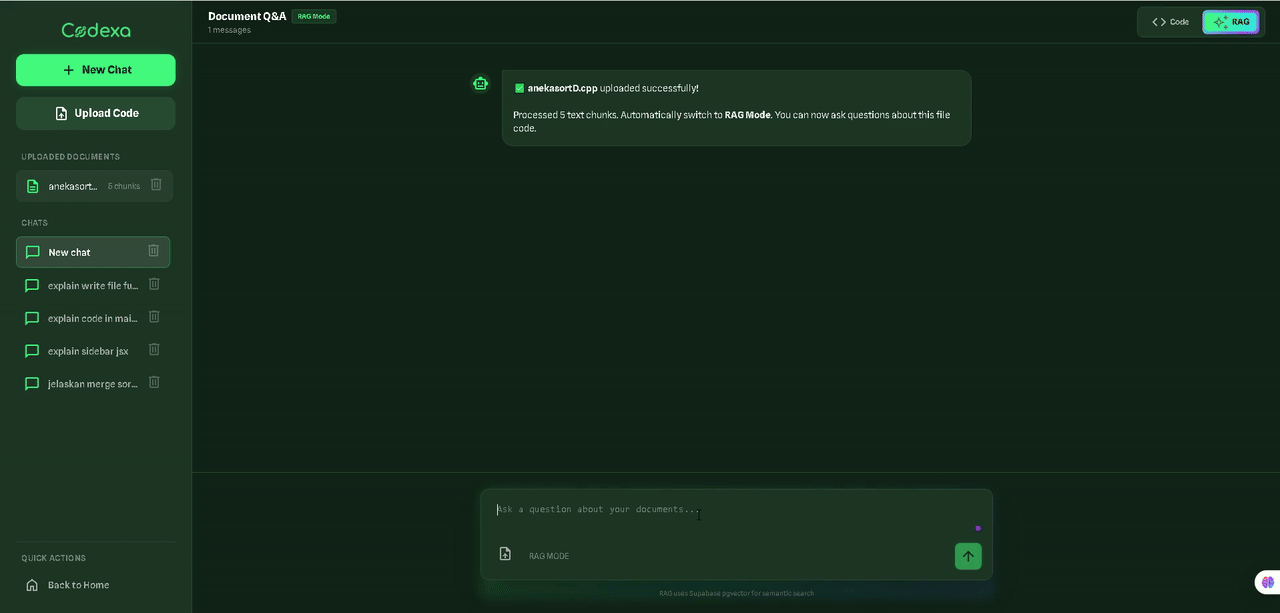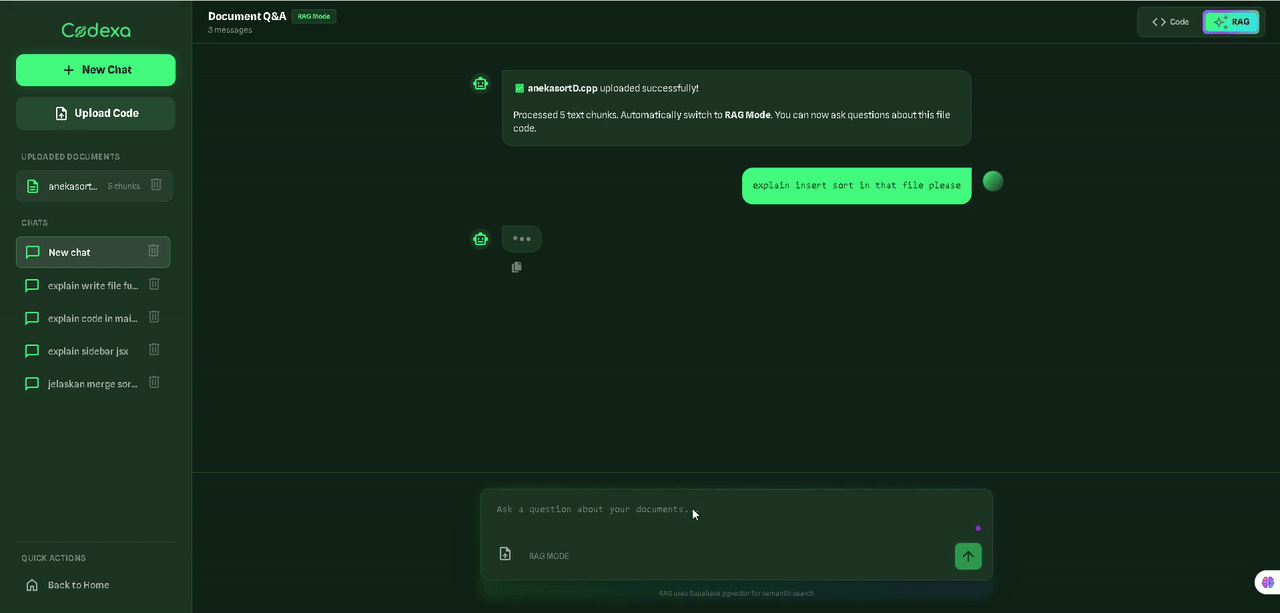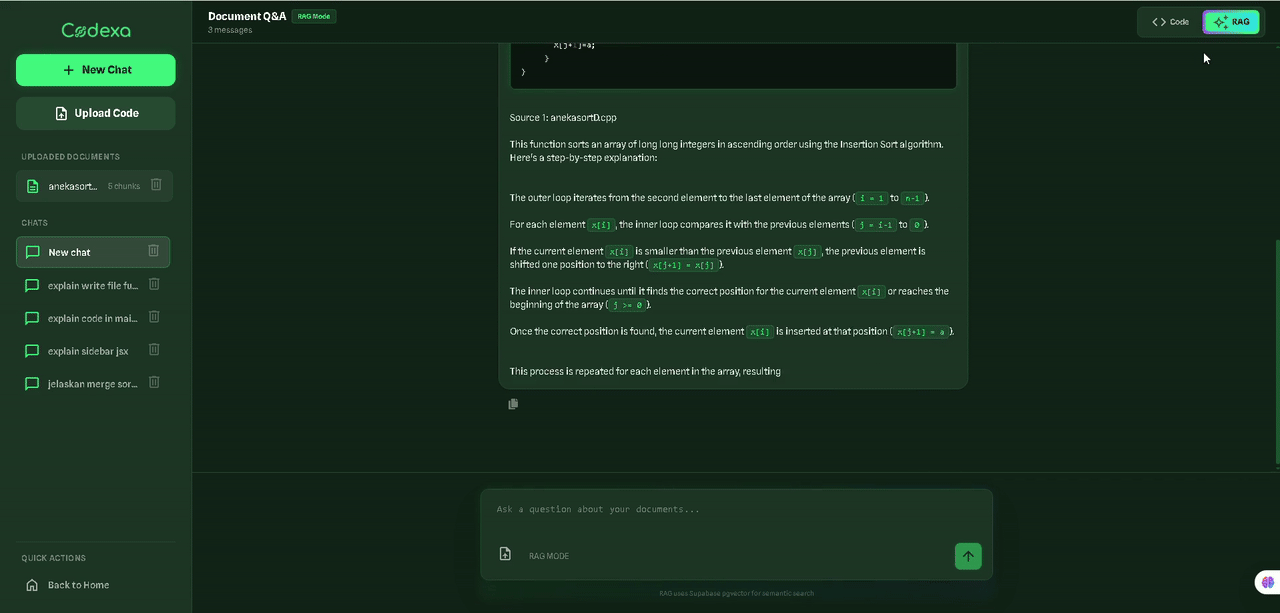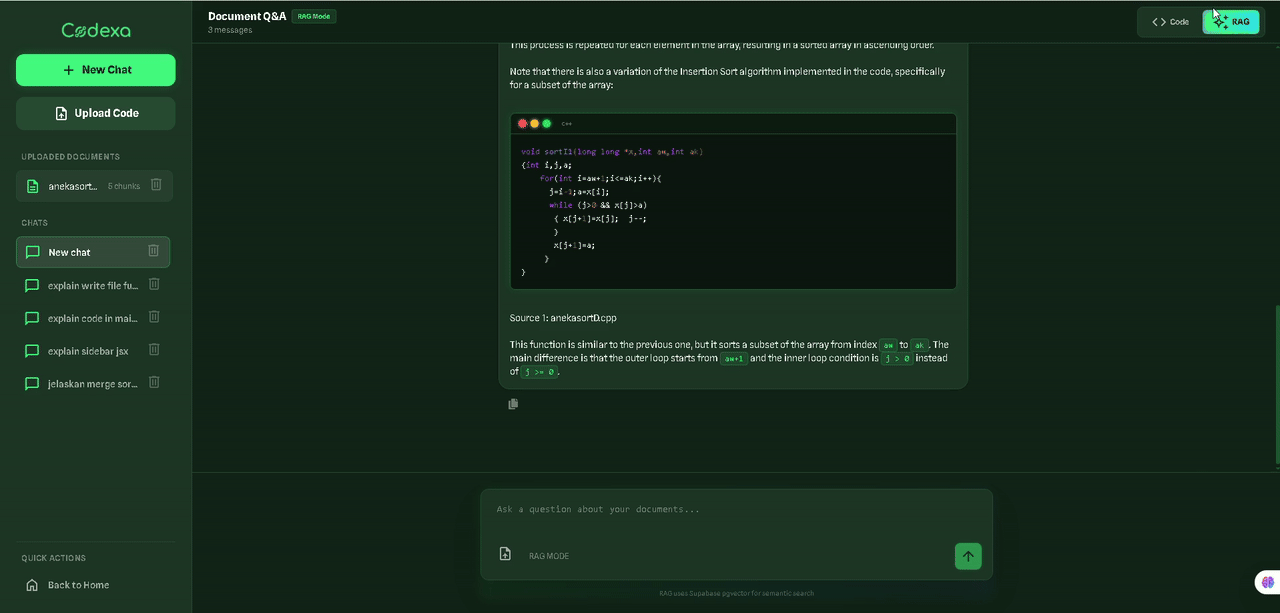
I set out to build an efficient, budget-friendly AI app, but the journey taught me a crucial lesson: balancing performance and cost is rarely simple—it requires navigating deep technical trade-offs.
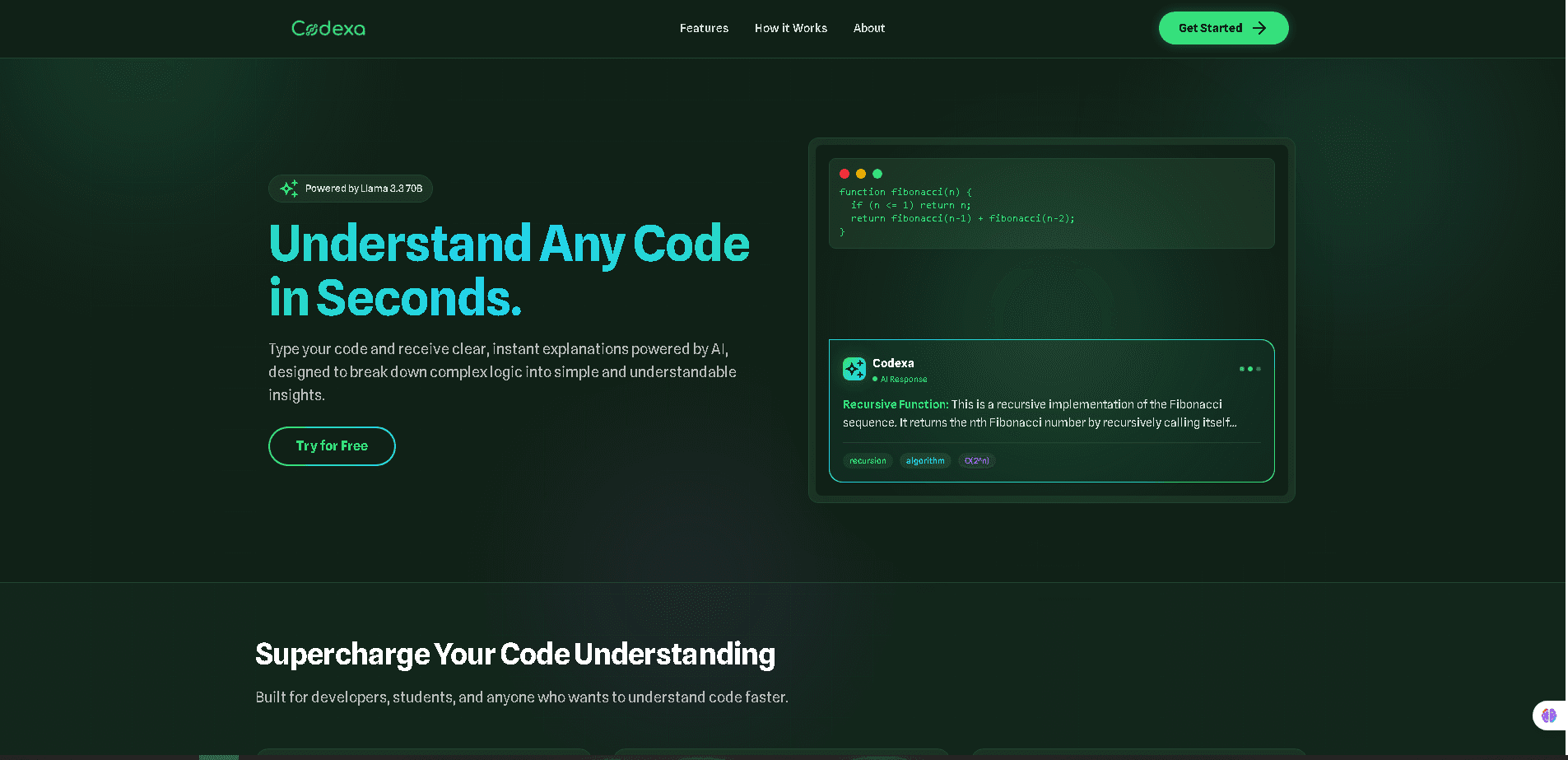
function fibonacci(n) {
if (n <= 1) return n;
return fibonacci(n-1) + fibonacci(n-2);
}Recursive Function: This is a recursive implementation of the Fibonacci sequence. It returns the nth Fibonacci number by recursively calling itself...
Built for developers, students, and anyone who wants to understand code faster.


Reduced response time from 15s to <500ms using real-time LLM token streaming via SSE.
15s → <500msProduction RAG pipeline with LangChain and Llama-3.3-70B achieving high precision at 75% similarity threshold.
pgvector poweredLocal embedding generation using Xenova Transformers.js, eliminating external API costs entirely.
Zero API costsOptimized with embedding model preloading and lightweight 384-dim vector embeddings.
384-dim vectorsWatch how Codexa transforms complex code into clear, understandable explanations with just a few clicks.